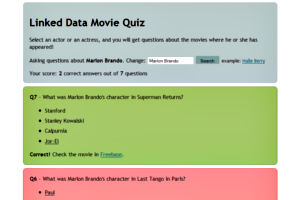
Tired of doing repetitive tasks on some emails you receive? AppEngine Mail Processor is here to solve your problems!
Sometimes we receive emails that ask us to click on a link to confirm an account, or to send some data or any other task. Everything that is triggered by an email and that requires an automatic task to process it can be programmed using this application. If the automatic task runs fine you will not have to do it yourself, if the task doesn’t work because something has changed you can always do it manually and fix it for the next time. You will not lose the time to repeat the same task again and you will get a report with the results.
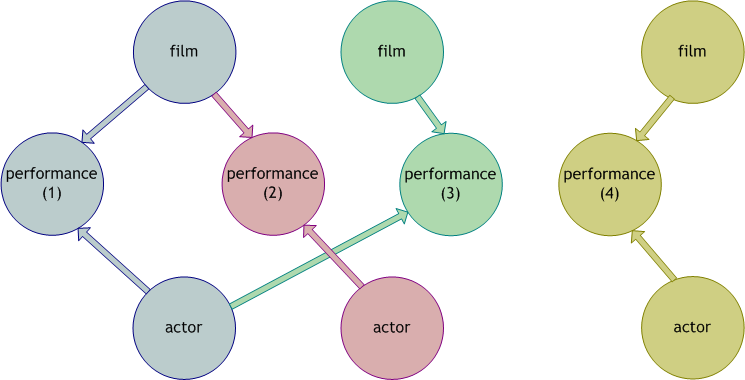
AppEngine Mail Processor is an application designed for Google’s AppEngine application server. This application will receive the emails you choose and execute the actions or tasks you want over them. It is possible to add new actions to do anything you need to do. The application will then send the result of the action back in a mail, you just need to check the result mail and forget it.
AppEngine Mail Processor is open source so you can download it and use it in your applications. You can configure your own tasks or extend the application functionality. If you do, tell us about it!
To install it in your own AppEngine application follow this steps:
- Create your account and basic application in Google’s AppEngine (http://appengine.google.com/,ô http://code.google.com/appengine/). We used AppEngine for Java version 1.4.0, so use a compatible version.
- Download AppEngine Mail Processor code from GitHub:ô https://github.com/lamboratory/AppEngine-Mail-Processor and add it to your application code.
- Modify web.xml file to process mails by the com.lamboratory.mail.Mail class.
- Configure the application to reveive emails in appengine-web.xml.
- Implement Action interface if you want to use a new action.
- Upload your application to AppEngine.
- Change the mail address in Mail.java class to a valid administrator of you AppEngine application. This is required to send emails from AppEngine.
- Upload your application to AppEngine.
- Create a filter in your mail to forward emails based on subject or sender to the desired AppEngine, depending on the Action to execute. To execute example ClickLinksAction you can use click_links@<yourAppEngineApplicationId>.appspotmail.com (Note it’s different fromô <yourAppEngineApplicationId>.appspot.com).
- If you want to check the logs for your application you’ll need to raise log level to info using logging.properties file.
- Forget about repeating the same task again!

![]()
![]()
Note: The idea of this application included having the response mails delivered to your real email account and added to the same thread than the original mail. If this worked you could then create a new filter that archived the full conversation based on the automatic response. Currently, AppEngine deletes the mail headers that are used for thread view in emails like gmail. If you also think that would be useful you can check these links:
http://code.google.com/p/googleappengine/issues/detail?id=2802
http://groups.google.com/group/google-appengine/browse_thread/thread/b80737b41f53541f

 La idea es enriquecer la navegaciû°n habitual, proporcionando -no intrusivamente, en un panel desplegable- informaciû°n bûÀsica de los usuarios de twitter que aparezcan en cualquier pûÀgina. (Al lado de cada nombre encontrado habrûÀ una imagen que permitirûÀ desplegar la informaciû°n, y sobre el icono de la extensiû°n aparece el nû¤mero de twitteros encontrados, pudiûˋndose desplegar la informaciû°n tambiûˋn desde ahûÙ.) Con esto se consigue no tener que abrir una nueva pestaûÝa para ver esa informaciû°n, ya que muchas veces encuentra uno nombres de twitteros en alguna pûÀgina, pero da pereza abrir sus perfiles para saber mûÀs de ellos. AdemûÀs, haciendo login con la cuenta de twitter, la extensiû°n dice si se sigue o se es seguido por los usuarios encontrados, permitiendo hacer follow directamente desde el desplegable. (Por tanto, aunque sea una extensiû°n de twitter, creemos que no es otro cliente de twitter como extensiû°n, sino un concepto diferente:-)
La idea es enriquecer la navegaciû°n habitual, proporcionando -no intrusivamente, en un panel desplegable- informaciû°n bûÀsica de los usuarios de twitter que aparezcan en cualquier pûÀgina. (Al lado de cada nombre encontrado habrûÀ una imagen que permitirûÀ desplegar la informaciû°n, y sobre el icono de la extensiû°n aparece el nû¤mero de twitteros encontrados, pudiûˋndose desplegar la informaciû°n tambiûˋn desde ahûÙ.) Con esto se consigue no tener que abrir una nueva pestaûÝa para ver esa informaciû°n, ya que muchas veces encuentra uno nombres de twitteros en alguna pûÀgina, pero da pereza abrir sus perfiles para saber mûÀs de ellos. AdemûÀs, haciendo login con la cuenta de twitter, la extensiû°n dice si se sigue o se es seguido por los usuarios encontrados, permitiendo hacer follow directamente desde el desplegable. (Por tanto, aunque sea una extensiû°n de twitter, creemos que no es otro cliente de twitter como extensiû°n, sino un concepto diferente:-)